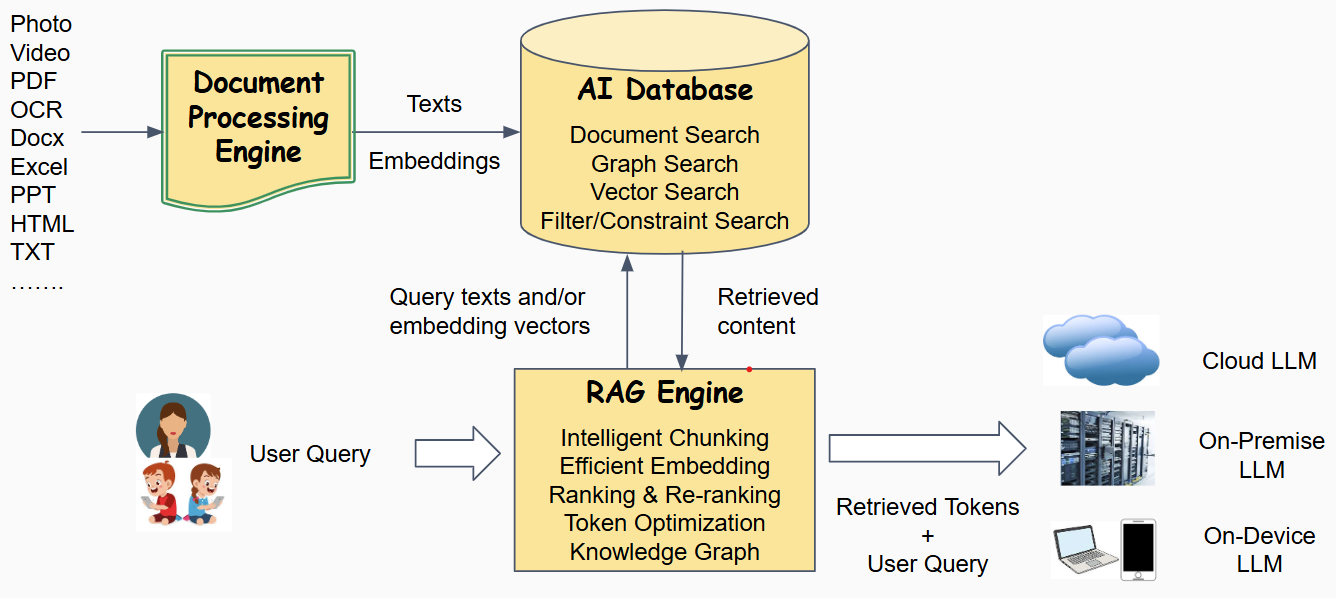
Retrieval-Augmented Generation (RAG) is a typical application pattern for Large Language Models (LLMs). In RAG, a (personal or enterprise) knowledge base is constructed using a Document Processing Engine and an AI Database. Instead of sending the user query directly to the LLM, the RAG engine first retrieves relevant documents, graph relations, and/or embedding vectors from the knowledge base. These retrieved contents, along with the original user query, are then passed to the LLM for generation. The LLM itself can be deployed in public or private cloud, on-premises, or on-device.
What Does VecML AI Database Offer?
The data stored in the AI database can include documents, graphs, and embedding vectors. When building a RAG pipeline, it is often convenient to leverage relational tables to store elements such as chat histories. Additionally, for mission-critical applications, it is desirable for the database to support transactional operations.
🎯 Vector Search
Semantic search using embedding vectors for AI applications.
Learn More → API tool →📄 Document Search
Store and search through documents with advanced full-text capabilities.
Learn More → API tool →🔗 Graph Database
Manage complex relationships and connected data structures.
Learn More → API tool →⚡ Transactional Operations
ACID compliance for mission-critical enterprise applications.
Learn More →AI Search: Quick Start for Developers
📚 Full VecML AI DB Documentation
🔑 Get API Key
1. Sign up a free VecML account.
Sign Up2. After login, generate an API key. Please save and keep the key at a safe place, it will only be seen once when created.
Get API KeyYou can manage your API keys in account center from the top-right panel.
🏗️ Create Project & Collection
Create a project called "RAG-example" and initialize a data collection "embeddings" within the project, with "dense" vector type and dimension 128. We will use Python as the example language.
import requests
import json
import numpy as np
import time
API_KEY = "replace_this_with_your_api_key"
BASE_URL = "https://aidb.vecml.com/api"
def make_request(endpoint, data): # helper function to make API calls
url = f"{BASE_URL}/{endpoint}"
response = requests.post(url, json=data)
print(f"Request to {endpoint}: HTTP {response.status_code}")
if response.text:
json_response = response.json()
return response.status_code, json_response
else:
return response.status_code, None
# Create a project
project_data = {"user_api_key": API_KEY, "project_name": "RAG-example", "application": "search"}
status, response = make_request("create_project", project_data)
# Initialize dataset
init_data = {"user_api_key": API_KEY, "project_name": "RAG-example", "collection_name": "embeddings",
"vector_type": "dense", "vector_dim": 128 }
status, response = make_request("init", init_data)📤 Insert Data
Upload your vector embeddings efficiently using batch operations with "/add_data_batch" endpoint. This endpoint is asynchronous: the server will respond with a job ID for /add_data_batch. You can call "/get_upload_data_status" endpoint to track the status of the job.
VecML also supports other data insertion methods like upload through files. See full documentation for RESTful API usage instructions.
# Generate and add 100 random vectors with /add_data_batch
vectors = np.random.randn(100, 128).tolist() # some random vectors
string_ids = ['ID_' + str(i) for i in range(100)] # dummy ids for each vector
attributes = [{"text": f"example text {i}"} for i in range(100)] # attributes of each vector, which can be arbitrary
batch_data = {"user_api_key": API_KEY, "project_name": "RAG-example", "collection_name": "embeddings",
"string_ids": string_ids, "data": vectors, "attributes": attributes }
status, response = make_request("add_data_batch", batch_data)
time.sleep(5)⚡ Build Index
Build an index for a data collection for fast and accurate similarity search, with a specified distance/similarity measure.
Attach index is asynchronous: call "/get_attach_index_status" to check the job status.
# Attach index with L2 distance
index_data = {"user_api_key": API_KEY, "project_name": "RAG-example", "collection_name": "embeddings",
"index_name": "L2_index", "dist_type": "L2" }
status, response = make_request("attach_index", index_data)
index_job_id = response["job_id"]
print(f"Got index job ID: {index_job_id}")
# Checking the indexing job status every 1 sec, query after the job is done
print("Waiting for indexing to complete...")
max_wait_time = 20
start_time = time.time()
while True:
status_data = {"user_api_key": API_KEY, "job_id": index_job_id}
status, status_response = make_request("get_attach_index_status", status_data)
if status_response.get("status") == "finished":
print("Indexing completed successfully")
break
if time.time() - start_time > max_wait_time:
print("Server busy - indexing timeout after 20 seconds")
exit(1)
print("Indexing in progress, checking again...")
time.sleep(1)🔍 Search & Query
After the index is built, query the index with a query vector and retrieve top-5 most similar vectors from the data collection.
# Search with query vectors
query_vectors = np.random.randn(2, 128).tolist() # generate two query vectors
search_data = {
"user_api_key": API_KEY, "project_name": "RAG-example", "collection_name": "embeddings",
"index_name": "L2_index", "query_type": "vectors",
"top_k": 5, "query_vectors": query_vectors
}
status, search_results = make_request("search", search_data)
print("Search results:")
for result in search_results["results"]:
matches = result["matches"]
query_id = result["query_vector_id"]
print("Query id: ", query_id)
for pair in matches:
print(f"ID: {pair['idx']}, L2 Distance: {pair['distance']}")🎉 Congratulations! You're all set to use VecML Vector Search!
More Tips on Using VecML Database
Here are some tips to help you make the most of VecML Database Cloud:
- Managing vector string IDs. The database requires that every vector is associated with a UNIQUE string ID as the identifier. This string ID will be used in insertion, search, retrieval, etc. While the database will assign automatically generated IDs to vectors if not provided, it is highly recommended that the user manages and uploads the vector string IDs to keep track of your own data.
- Check job status for async requests. Time consuming operations triggered by upload/insert data requests and indexing requests are all asynchronous---the server will immediately respond with the assigned job ID that will be run on the server. Make sure to call the corresponding check job status endpoints and confirm the jobs have finished successfully before further steps.
- Use meaningful metadata (attributes): Adding metadata (i.e. vector attributes) to your vectors enables powerful filtering capabilities.
- Start with sample datasets: Try with our sample datasets to understand how VecML works before uploading your own datasets.
Common Workflows
Here are some typical workflows for different use cases with VecML:
Text Semantic Search
Build a powerful semantic search engine for documents, articles, or product descriptions.
- Generate text embeddings using models like OpenAI's text-embedding-ada-002
- Upload embeddings to VecML with relevant metadata
- Create a search index with cosine similarity
- Implement search by embedding query text and searching the vector database
Image Similarity Search
Find similar images based on visual features and content.
- Generate image embeddings using a vision model
- Upload embeddings to VecML with image metadata
- Create an index optimized for image similarity
- Search using query image embeddings to find visually similar content
Recommendation Systems
Build personalized recommendation engines based on user behavior and item similarity.
- Create embeddings for users and items
- Store both in VecML with appropriate metadata
- Query similar items based on user preferences
- Implement hybrid filtering using metadata and vector similarity
Document Search
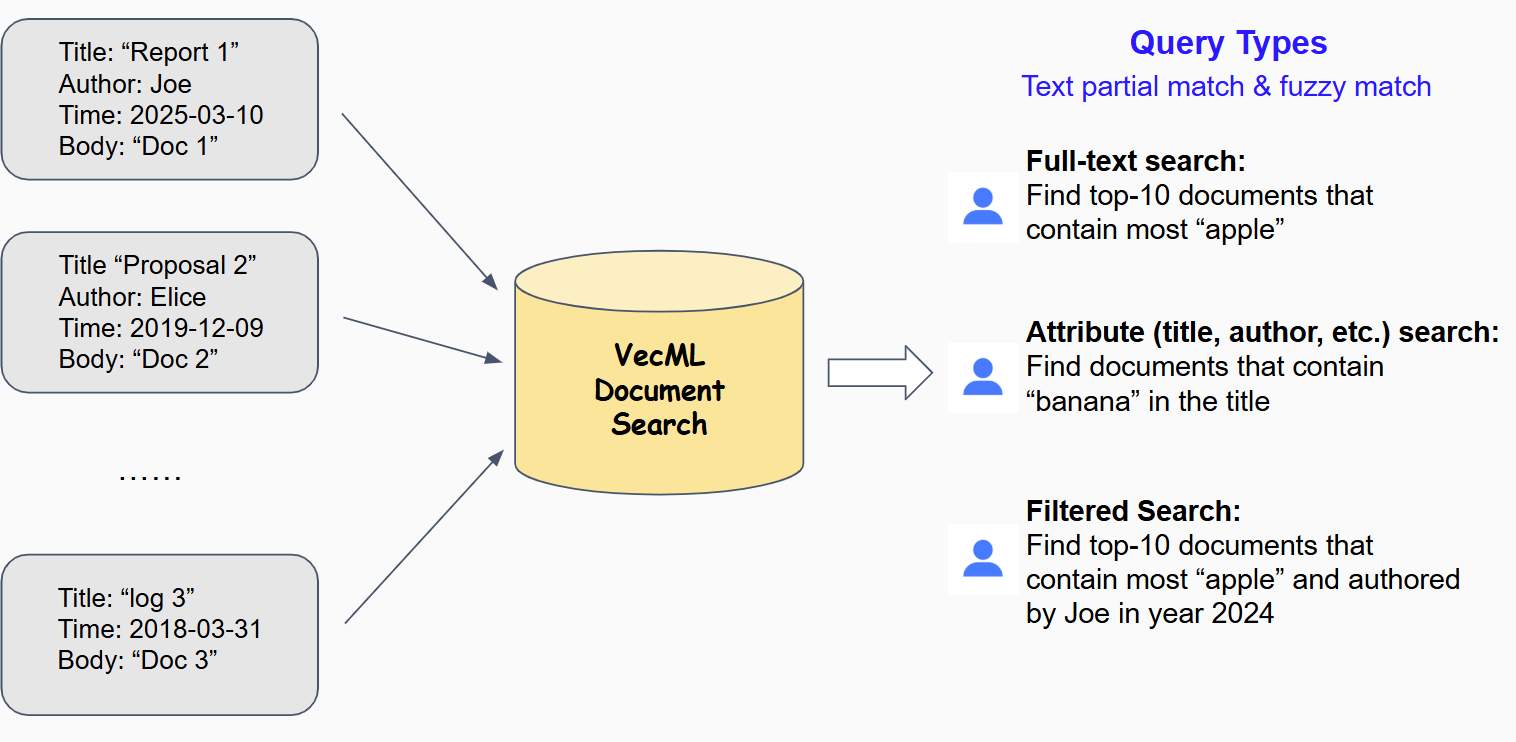
Powerful Document Database: Store, index, and search through documents with advanced querying capabilities including full-text search and attribute-based filtering.
Document Database (Fluffy Document) Documentation
A powerful NoSQL database for storing and retrieving document data with advanced querying capabilities. Supports full-text search with fuzzy matching and attribute-based queries.
Key Features:
• Document Storage: Store documents with metadata and custom attributes
• Full-Text Search: Search through document content with fuzzy matching
• Attribute Indexing: Create indexes on custom attributes for fast queries
• Flexible Querying: Query by content, attributes, or both
Code Example:
// Add documents with attributes
fluffyDocumentInterface.add_document("id1", "Doc 1", "path0", {{"title", "Hello"}});
fluffyDocumentInterface.add_document("id2", "Doc 2", "path1", {{"author", "Amy"}, {"title", "world"}});
// Attach/create an index for an attribute
fluffyDocumentInterface.attach_attribute_index("title");
// Query full-text with fuzzy string match
fluffy::InterfaceDocumentQueryResults doc_results;
fluffyDocumentInterface.search_documents("ample C++", 2, doc_results);
// Query attribute with fuzzy match
fluffy::InterfaceDocumentQueryResults attr_results;
fluffyDocumentInterface.search_attribute("ello", "title", top_k, attr_results);Vector Search
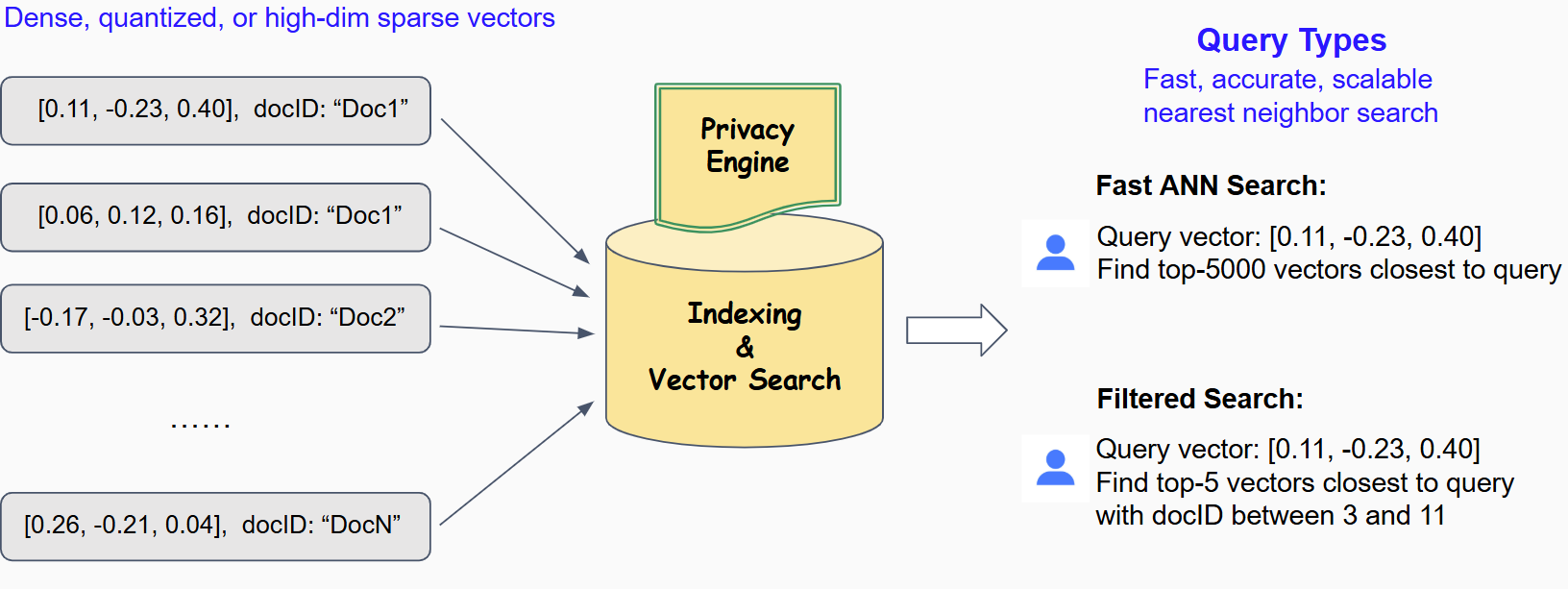
High-Performance Vector Database: Store and search high-dimensional vector embeddings with advanced similarity search, semantic matching, and AI-powered retrieval capabilities.
Vector Database (Fluffy Vector) Documentation
A cutting-edge vector database optimized for AI applications. Store, index, and search high-dimensional embeddings with lightning-fast approximate nearest neighbor (ANN) search, perfect for semantic search, recommendation systems, and RAG applications.
Key Features:
• High-Dimensional Storage: Efficiently store and manage vector embeddings of any dimension
• Similarity Search: Fast approximate nearest neighbor search with configurable distance metrics
• Semantic Matching: Find semantically similar content using AI-generated embeddings
• Scalable Indexing: Advanced indexing algorithms for optimal performance at scale
Code Example:
// Build fluffy vectors and insert to data collection
int dim = 3;
std::vector cpp_vec = [1, 2, 3];
std::unique_ptr fluffy_vec;
fluffyInterface.build_vector_dense(cpp_vec, fluffy_vec);
std::string date = "2025-03-11";
fluffy_vec->set_attribute("date", reinterpret_cast(date.data()), date.size()); // assign vector attribute
fluffyInterface.add_data("string_id", fluffy_vec);
// Create/attach and index for fast nearest neighbor search
fluffyInterface.attach_index(dim, "dense", fluffy::DistanceFunctionType::Euclidean, "index1");
// Build query and search, with the support of filtered search
std::vector query_vec = [3, 2, 1];
fluffy::Query query;
query.top_k = k; query.vector = vector.get();
fluffy::InterfaceQueryResults result;
fluffyInterface.search(query, result, "index1"); Graph Search
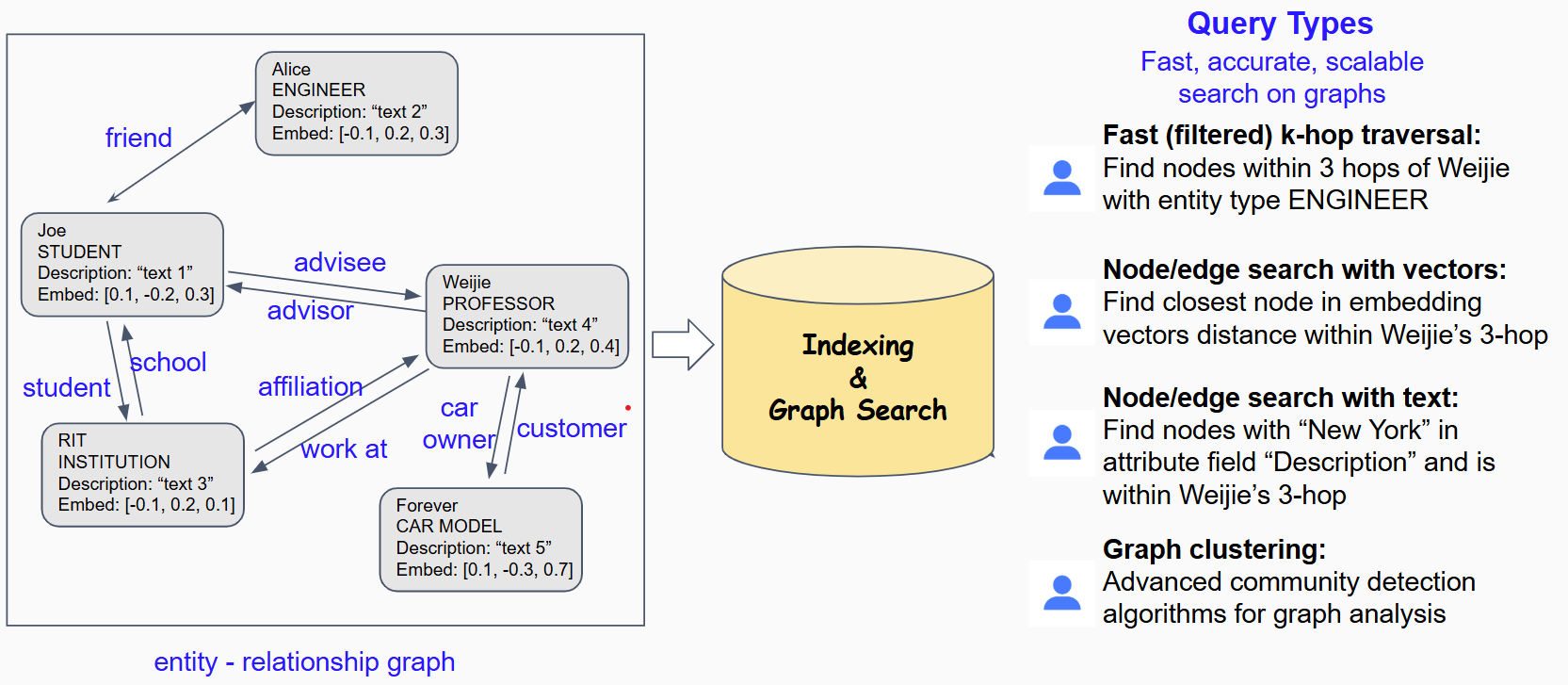
Advanced Graph Database: Store and query complex relationships between entities with powerful graph traversal and pattern matching capabilities.
Graph Database (Fluffy Graph) Documentation
A high-performance graph database for storing and querying interconnected data. Perfect for social networks, recommendation systems, knowledge graphs, and complex relationship analysis.
Key Features:
• Node & Edge Management: Create and manage nodes with properties and relationships
• Graph Traversal: Perform complex graph queries and path finding
• Pattern Matching: Find specific patterns and subgraphs within your data
• Relationship Analysis: Analyze connections and discover insights in your network
Code Example:
Data Format and Sample Datasets
VecML Database supports a variety of data formats for vector storage and retrieval. Below you'll find sample datasets to help you get started with testing and exploring the capabilities of our vector database.
Quick Start Tip
Download one of our sample datasets and upload it to your VecML project to start experimenting with VecML's powerful vector search functionality within minutes.
openai-embedding (JSON Format)
Embedding vectors released by OpenAI (Hugging Face), dim = 1536. ID field: "_id", vector data field: "openai". Other fields (which can be optionally saved as vector attributes): "title", "text", "date".
openai-embedding-1k.json (34MB, 1,000 vectors) | openai-embedding-10k.json (332MB, 10,000 vectors) | openai-embedding-query.json (3.4MB, 100 vectors)personahub-embedding (Binary Format, Float32 Type; dimension info is not included)
Embedding vectors of HuggingFaceFW/fineweb-edu dataset using Alibaba's gte-large-en-v1.5 model (Hugging Face), dim = 1024.
personahub_50k.bin (195MB, 50,000 vectors) | personahub_query.bin (3.9MB, 1,000 vectors)MNIST (Binary Format, UInt8 Type; dimension info is not included)
MNIST hand-written digit image dataset, dim = 784. All data (pixel) values are integers in [0, 255].
mnist_train.bin (44.8MB, 60,000 vectors) | mnist_test.bin (7.5MB, 10,000 vectors)CoverType (CSV Data Matrix Format)
A benchmark machine learning dataset from UCI repository, dim = 54, # of classes: 7. Label column: "Cover_Type"
covertype_train.csv (67.6MB, 531,012 samples) | covertype_test.csv (6.4MB, 50,000 samples)svmguide3 (LIBSVM Sparse Format)
A small LIBSVM sparse format dataset from LIBSVM website, dim = 21, # of classes: 2. Each line starts with the label (integer).
svmguide3_train.svm (300KB, 1,243 samples) | svmguide3_test.svm (11KB, 41 samples)Sample Dataset Use Cases for Vector Search
OpenAI & Personahub Embeddings
Ideal for: Semantic search, document similarity, content recommendation
The OpenAI embeddings collection contains text embeddings generated using OpenAI's models. The Personahub embeddings collection contains embeddings produced by Alibaba's models. These embeddings capture semantic meaning of text, making them perfect for building search systems, recommendation engines, or content organization tools.
Quick start:
- Download the openai-embedding-1k.json sample
- Create a new dataset in your VecML project
- Specify "_id" as the ID field and "openai" as the vector field
- Import the file and build a search index
- Use the openai-embedding-query.json file to test similarity search
MNIST
Ideal for: Image similarity search, classification, clustering
The MNIST dataset contains handwritten digit images, represented as 784-dimensional vectors (28x28 pixels). This dataset is perfect for testing image search capabilities, building digit classifiers, or exploring clustering algorithms.
Quick start:
- Download the mnist_train.bin sample
- Create a new dataset with dimension=784 and type=UInt8
- Import the file and build an index
- Use mnist_test.bin for query testing
Dataset Import Guidelines
Follow the following guidelines to ensure your dataset can be successfully imported and parsed into VecML Database:
| Format | Required Item | Optional Parameters | Best For |
|---|---|---|---|
| JSON | Whether containing field name | ID/vector/attribute fields; Extra string ID | Datasets with rich metadata |
| Binary | Dimensionality, data type | Extra string ID | Large datasets, performance-critical applications |
| CSV | Whether containing column name | ID/attribute column; Extra string ID | Tabular data, analytics workflows |
| LIBSVM | Proper key:value format | Extra string ID | Sparse datasets, classification tasks |
Supported Data Formats
VecML Database supports multiple data formats to accommodate different use cases and data sources. Below are detailed descriptions of each format and how to use them effectively.
JSON (JavaScript Object Notation) format is ideal for storing vector data along with metadata. Each vector is represented as a JSON object with fields for the vector values and additional metadata.
Key features:
- Human-readable format
- Supports metadata for vectors. Currently, we only support the flat structure of metadata without nested structures. See the below example.
- Easy to process with standard libraries
Example JSON with field names:
Example JSON with NO field names:
Import tips:
When importing JSON data that contains field names, specify the "vector data field" (e.g., "openai") and optionally the "ID field" (e.g., "_id"). You can select any additional fields which will be stored as metadata that can be used for filtering and retrieval.
Binary format is efficient for storing large vector datasets and is available in different numerical types. Currently we support Float32 and Uint8 data types. For Float32, every consecutive 4 bytes will be read as a Float32 value; for UInt8, every byte will be read as a unsigned 8-bit integer value. This format stores raw vector values without metadata, making it compact and fast to process, suitable to large-scale applciations.
Key features:
- Space-efficient storage
- Fast loading and processing
- Ideal for large datasets
Import tips:
When importing binary data, you need to specify:
- Vector dimensionality (e.g., 1024 for personahub, 784 for MNIST)
- Numerical type (Float32, UInt8, etc.)
CSV (Comma-Separated Values) format is widely used for tabular data and is supported by many tools and platforms. CSV files can be used to store vector data where each row represents a vector and its associated attributes and/or metadata.
Key features:
- Compatible with spreadsheet software and data analysis tools
- Easy to generate and edit
- Good for datasets with consistent schema
Import tips:
When importing CSV data:
- The CSV file may or may not contain headers (column names). Based on the data preview, specify whether the data has headers or not.
- Specify all the attribute/metadata columns. For training maching learning models, include the class label (for classification) or response (regression) as attributes.
LIBSVM format is designed for sparse datasets where most feature values are zero. It uses an efficient key:value representation that only stores non-zero values.
Key features:
- Extremely efficient for sparse and high-dimensional data
- Commonly used in machine learning applications
- Reduces storage and processing requirements
Import tips:
When importing LIBSVM data, if the first value on a line is a single integer, it will be treat as the label. If the line starts directly with key:value pair, then no label is read for that line.